

Why Linked Data Is the Key to Helping Your Library Get Discovered
Machine-Readable Cataloging, or MARC records, have long been a cornerstone of modern library cataloging standards. MARC standards took libraries from card to computerized catalogs, eliminating the need for cumbersome and expensive union catalogs and ushering in an era where any user could easily conduct a digital search across a library’s entire catalog.
Limitations of MARC Records
Unsurprisingly, this data type, understandable only by librarians and created during the era of punch-card programming, has its limitations, including the following:
- Even within the library community for which it is designed, MARC presents difficulties for librarians trying to integrate MARC records with non-MARC data.
- Despite being maintained and accessed on computers, MARC records are designed for human use and consumption. They are encoded in natural language, rather than as data, and therefore lack any extensive ability to interact with machine applications.
- MARC records do not integrate with the Semantic Web, which is an extension of the World Wide Web that allows data to be shared and reused across different applications, helping to provide more visibility to pieces of information. In layman’s terms, the Semantic Web creates a highly searchable database of all the information on the Web, which means people can find better information faster.
These limitations expose the need for something more modern, flexible and web-ready than MARC records. Linked data meets this need.
What Is Linked Data?
Linked Data has been defined as the following:
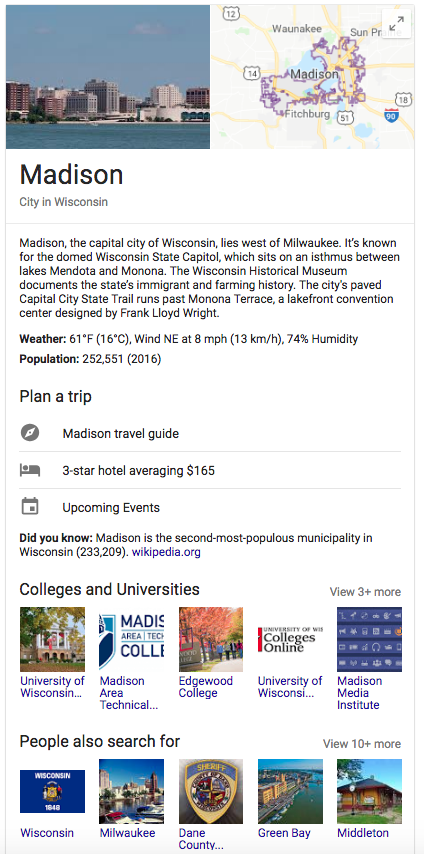
The Google Knowledge Graph is an example of Linked Data in action.
- A set of best practices for publishing data on the Web
- The practice of coding data with semantic meaning for computer readability
- The use of standards to provide meaning for computers
While the technical aspects of Linked Data and the Semantic Web can be difficult to understand for the layperson, we have all seen it in action in the real world. Google’s Knowledge Graph — the box that shows up to the right of your Google search results, with information on your search topic drawn from all over the Web — is a great example.
Services like Google’s Knowledge Graph are made possible by tagging pieces of content to indicate relationships between them. These tags allow data to be linked with other related data. This creates webs of meaning on the Semantic Web instead of the standard one-to-one HTML link relationship. This means your computer can deliver more relevant information without you having to dig for it.
The interests that drive Linked Data are the same as those that drive MARC and similar standards — the need to construct vocabularies, identify and describe properties of resources and exchange and aggregate this metadata — all to help resources get found. The problem with the relationships in traditional library metadata, or MARC records, is that they exist in databases controlled by strings of text with markers that are used by software to dynamically display the content. These dynamically formatted pages are part of the “hidden Web,” and they are not indexed by search engines.
This is where Linked Data comes in, providing the markup that teases out structural and semantic meaning and allowing for the automatic linking between related things. Or, to put it simply, Linked Data helps return better results when someone searches for a topic online.
What Does Linked Data Mean for Your Library?
The implications of using Linked Data for library records are vast. For one, Linked Data will boost exposure of libraries’ events, programming and collections. People, including readers, increasingly go to search engines first when seeking information. According to GoodReads, 19% of people discover books via online searches. Yet because search engines do not index MARC records, libraries’ collections are not part of the Semantic Web, effectively cutting off visibility of what the library offers to a large subsection of potential users.
Bibliographic records represent the hard work of many librarians attempting to make their libraries’ collections accessible; preventing them from being visible on the Web is counterproductive and unnecessarily restrictive. Patrons shouldn’t have to navigate to the library website to access what the library provides. Instead, libraries can and should begin meeting patrons where they most often seek information and resources — on the open Web.
Linked Data also increases the probability of serendipitous discovery of your collection. Users cannot search for information or resources of which they are unaware, and today’s library catalogs offer little more than “search and retrieve” behaviors. By providing automatic relationship links between data sets, Linked Data increases the likelihood that users will discover helpful “unknown” resources when they do an online search.
Not only does Linked Data benefit patrons, it benefits librarians as well. Because Linked Data allows for the layering of commonly shared data about books and materials with library-specific information, such as location and availability, librarians won’t have to repeatedly create the same data.
Bringing Linked Data to Libraries Everywhere
Libraries around the globe have begun to recognize the value of Linked Data, and there are already a number of initiatives underway that are helping libraries leverage the Semantic Web. For instance, the Libhub Initiative is actively collecting MARC records from partnering libraries and converting the MARC data into Linked Data. The Library of Congress (LOC), realizing that library metadata is not relevant to a Linked Data environment, has made significant moves toward embracing Linked Data.
The LOC’s Bibliographic Framework Initiative (BIBFRAME) has the goal of translating the MARC 21 format to a Linked Data model without sacrificing the details. BIBFRAME will allow search engines not only to find the information within records, but to do something with that information. For instance, if a user were to do a Google search for The Great Gatsby, search results could provide information that libraries already collect and manage that is not currently exposed on the Web. Links to the author, publisher, and other relevant information, such as resource location — possibly even down to the branch and call number — could be easily and immediately accessible to Web users.
While BIBFRAME is still a work in progress, it is one of many examples of the realization that “libraries must be not only on the Web, but of the Web,” as noted by Robin Hastings, Director of Technology for Northeast Kansas Library System. The move from a document-centered model to a data-centered model — one that can be used by both humans and computers to foster new connections and webs of information — may not be an easy one, but it is an increasingly necessary one.
Interested in hearing more about how Demco Software is supporting this move from legacy data standards to Linked Data? Join our mailing list.
Additional Resources
- Ending the Invisible Library
- LinkedData.org
- Linked Data in Libraries: Status and Future Direction
- Transforming Library Metadata into Linked Library Data
![]()
Find New Ways to Engage
Join our mailing list to get inspiring and informative content delivered straight to your inbox.
Last Name*
Email*
Related Resources

You Responded, We Listened: Wandoo Reader Survey Results and Plans for 2019
Discover what we learned from our Wandoo Reader customer survey and how we are using the results to enhance current features and develop new functionality for 2019.
read more
Explore the Benefits of Offering Online and In-Person Learning at Your Library
Are you interested in offering online learning opportunities while still continuing to hold in-person programs at your library? Explore the benefits of both learning formats and get ideas on ways they can complement each other.
read more
4 Signs that Your Community Is Ready for a Library Mobile App
Are you thinking about investing in a library mobile app, but you’re not sure if your patrons would use it? Use this checklist to help you determine if your community is truly ready for a library mobile app.
read more

